
Bildung und Forschung erreichen langsam den digitalen Raum, auch in den Geisteswissenschaften. An der Goethe Universität Frankfurt wird die Studienverwaltug über ein System QIS/LSF organisiert und Lehrenden steht das e-learning System OLAT (Offizielle Webseite) zur Verfügung um Lernmaterialen an Studierende zu verbreiten. Große Teile der Bibliothek sind mittlerweile im Web durchsuchbar. Lehrenden und Studierenden steht Citavi als Bibliographiedatenbankprogramm zur Verfügung. Zusätzlich haben wir dank der deutschen Nationallizenzen Zugriff auf weite Teile der großen Online-Literaturdatenbanken (z.B. JSTOR, Project Muse).
Was aber machen die Studierenden (zumindest in den Sozial- und Kulturwissenschaften, ich habe den Verdacht, dass es hier Unterschiede zu den Naturwissenschaftlern gibt)? Wir organisieren uns (immerhin) über Facebook, wir benutzen gezwungenermaßen Word/Open Office Writer/Libre Office Writer um unsere Hausarbeiten zu schreiben. Dabei belassen wir es dann für gewöhnlich auch. Wir benutzen die Bibliothekswebseite um Bücher zu finden, und selbst wenn sie im Open Access verfügbar sind, laufen wir in die Bibliothek, um sie auszuleihen oder direkt dort zu lesen. Dann schreiben wir beim fünften Mal, dass wir das gleiche Buch zitieren, noch einmal alle bibliographischen Daten ab.
Das geht mittlerweile einfacher und effektiver! Und es sollte doch in unserem Interesse sein, Arbeiten für die Uni effektiv zu gestalten, um mehr Zeit wahlweise fürs Weiterlesen oder für mehr Freizeit zu haben. Natürlich gibt es vor allem ein Vermittlungsproblem und das, zugegebenermaßen, nicht nur zwischen Lehrenden und Studierenden. Noch heute gibt es Lehrende, die ihre Bibliographie lieber aus dem eigenen Karteikartenkatalog abschreiben als sie einfach zu copy-pasten. Und dann ist es nur folgerichtig, dass diese Dozenten niemandem vermitteln können, dass es mit dem technischen Fortschritt auch große Arbeitserleichterungen in der Wissenschaft gibt.
Hier also nun eine kurze Einführung zu JabRef, einem Programm zur Verwaltung von Bibliographiedatenbanken1. JabRef ist ein relativ simples aber extrem gut anpassbares Programm, deshalb benutze ich es. Zotero, die vielleicht wichtigste Alternative, mit mehr Funktionen und schönerem Interface, benutze ich nur wenn es nicht anders geht, deshalb wird es hier nicht vorgestellt. Hier aber wenigstens die Wikipedia-Seite von Zotero.
Im Anschluss geht es ein wenig um gängige Formate, in denen man bibliographische Informationen maschinenlesbar speichern kann.
JabRef - Warum?
JabRef ist ein freies, Java-basiertes Bibliographieprogramm. Das heißt, dass es Plattformunabhängig läuft, solange Java installiert ist. Zusätzlich speichert es seine Datenbank(en) in einfachen Textdateien und benutzt dafür ein gängiges, uniformes, das heißt, dass die Datenbank einfach in andere Programme transferierbar ist, sollte es JabRef irgendwann nicht mehr geben. Andererseits kann es so relativ leicht zu Schwierigkeiten beim Speichern kommen. Es empfiehlt sich regelmäßig Backups zu machen.
JabRef ist kostenlos. Um nun also mit der eigenen Bibliographiedatenbank anzufangen, geht man zuerst zur Projektwebseite und lädt sich das Programm herunter, installiert und öffnet es. Dann erstellt man eine neue Datenbank durch einen Klick auf das Symbol links neben dem Speichersymbol oder im „File"-Menü ganz oben.
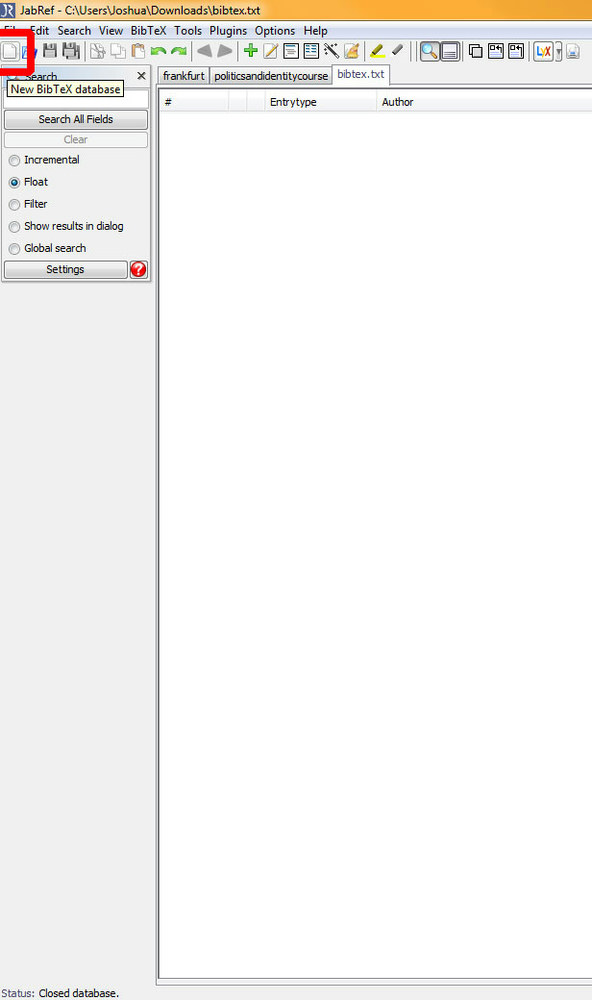
Jetzt kann man schon mit dem Eingeben anfangen. Um die Eingabemaske zu öffnen, klickt man oben in der Mitte auf das grüne „+"-Symbol. Als erstes wird man nun gefragt, zu welcher Kategorie der neue Eintrag gehört, ob es sich um ein Buch handelt, einen Artikel, um Konferenz-Proceedings, eine Masterarbeit usw.
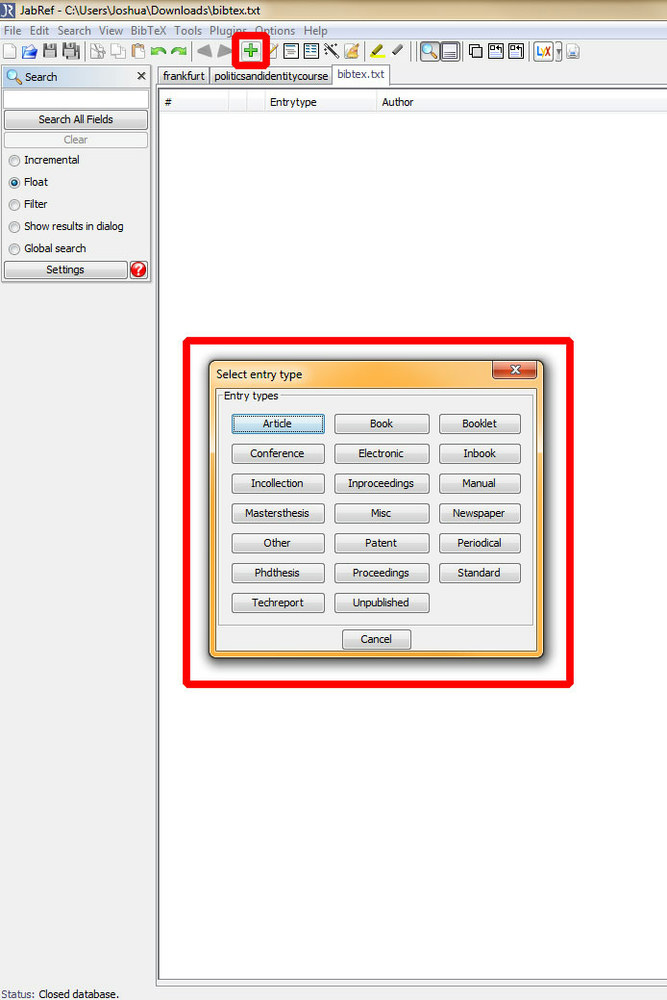
Jetzt öffnet sich am unteren Bildrand die volle Eingabemaske. Sortiert ist sie in Reitern mit Optionen entsprechend der Art von Eintrag, die man vorher ausgewählt hat. Z.B. braucht ein Buch keine Option um zu bestimmen, zu welchem Journal es gehört und ein Artikel aus einem Journal braucht keine Informationen zum Verleger.
Zusätzlich gibt es Felder, die für jeden Eintrag gelten (markiert durch ein braunes Quadrat im Reiter). Hier kann man Informationen zum Speicherort (falls man eine digitale Kopie hat), die URL, den Abstract (gilt effektiv aber auch für Kladdentexte etc.) und, wichtig, Schlagworten notieren. Man gibt nun also die Informationen ein, klickt den Zauberstab links neben der Eingabemaske, um dem neuen Eintrag einen eindeutigen Identifikationswerk zuzuweisen und wiederholt denselben Prozess für jeden neuen Eintrag.
Beim ersten Speichern (Diskettensymbol oben links oder STRG-S) nach dem Erstellen einer neuen Datenbank kommt jetzt die Frage, an welchem Ort die Datenbank zu speichern sei. Entsprechend lautet nun auch der Name der Datenbank oben im Reiter.
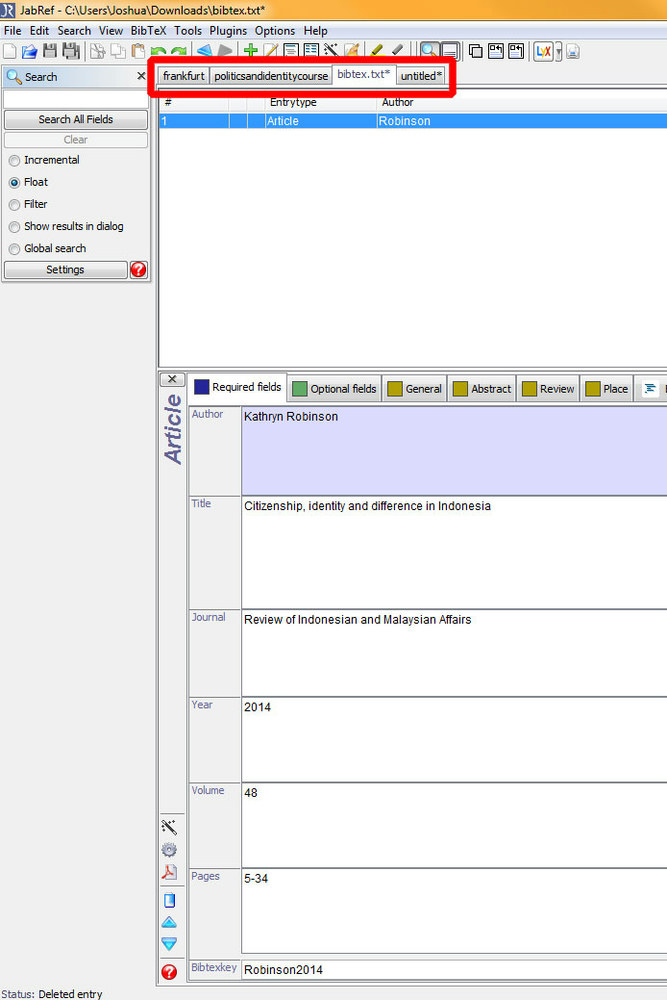
Besonders das Setzen von Schlagworten ist leicht zu übersehen macht aber viel Sinn. Sind die Schlagworte richtig gesetzt, bietet JabRef eine sehr nützliche Suchfunktion (STRG-F). Einerseits verliert man bei einer zu großen Datenbank relativ leicht den Überblick ohne die Suchfunktion nutzen zu können, andererseits hilft es gerade wenn man einmal eine größere Datenbank hat einfach Schlagworte eingeben zu können und schon einmal die bekannte Einstiegsliteratur versammelt zu haben.
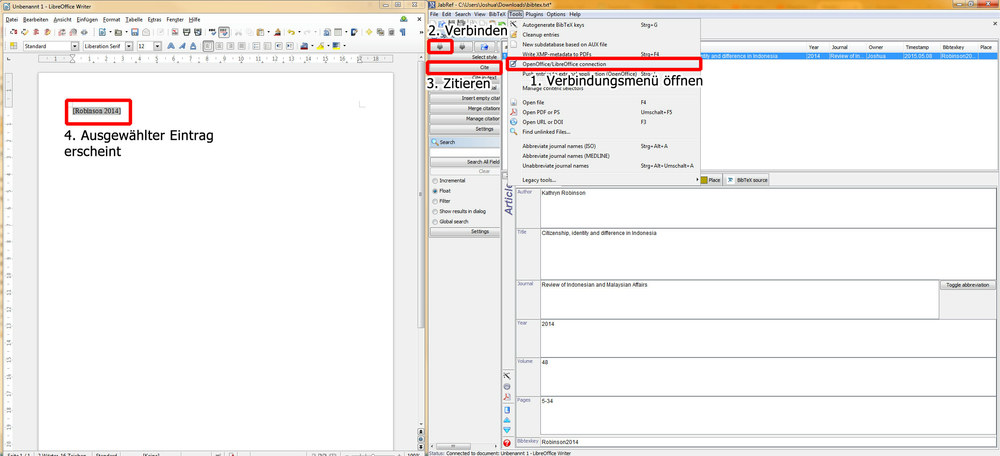
Neben der Suchfunktion bietet JabRef noch eine Reihe wichtiger Funktionen, vor allem das automatische exportieren von Bibliographischen Einträgen in eine Reihe von Programmen. Für die Asienwissenschaften ist hier wohl vor allem die Verknüpfung mit Open Office/Libre Office interessant. Öffnet man erst sein Textverarbeitungsprogramm und klickt dann auf „Open Office/Libre Office Connection" unter dem Menüpunkt „Tools". Links erscheint nun ein Menü mit Stromstecker-Symbolen ganz oben. Ein Klick auf das Linke verbindet die Programme und lässt JabRef das Zitat direkt in den Text eintragen. Dazu reicht ein Klick auf „Cite".
Eine andere nützliche und einfache Funktion ist „Cleanup entries". Mit dieser Funktion kann man seine PDFs, so man PDFs hinzugefügt hat, automatisch umbenennen lassen.
Neue Eingabeoptionen
Eine Anpassungsmöglichkeit, für die man keinerlei Art Code lesen können muss, ist das Hinzufügen von neuen Feldern für Informationen. Beispielsweise habe ich meine Bücher zuhause vertagt, um sie später besser finden zu können. Die Verwaltung mache ich mit JabRef, aber ohne Anpassungen hat JabRef keine Eingabeoption gezielt für den physikalischen Aufbewahrungsort des eingetragenen Buches o.ä. Was tun? Eine einfügen.

Hierzu öffnet man im Menü „Options" entweder „Customize entry types" oder „Set up general fields", je nachdem ob man das Feld nur für bestimmte Arten von Einträgen (also z.B. Bücher oder Artikel) oder einfach für alle Arten von Einträgen hinzufügen möchte. Im konkreten Fall einer Verschlagwortung der eigenen Bücher wäre das das Letztere.
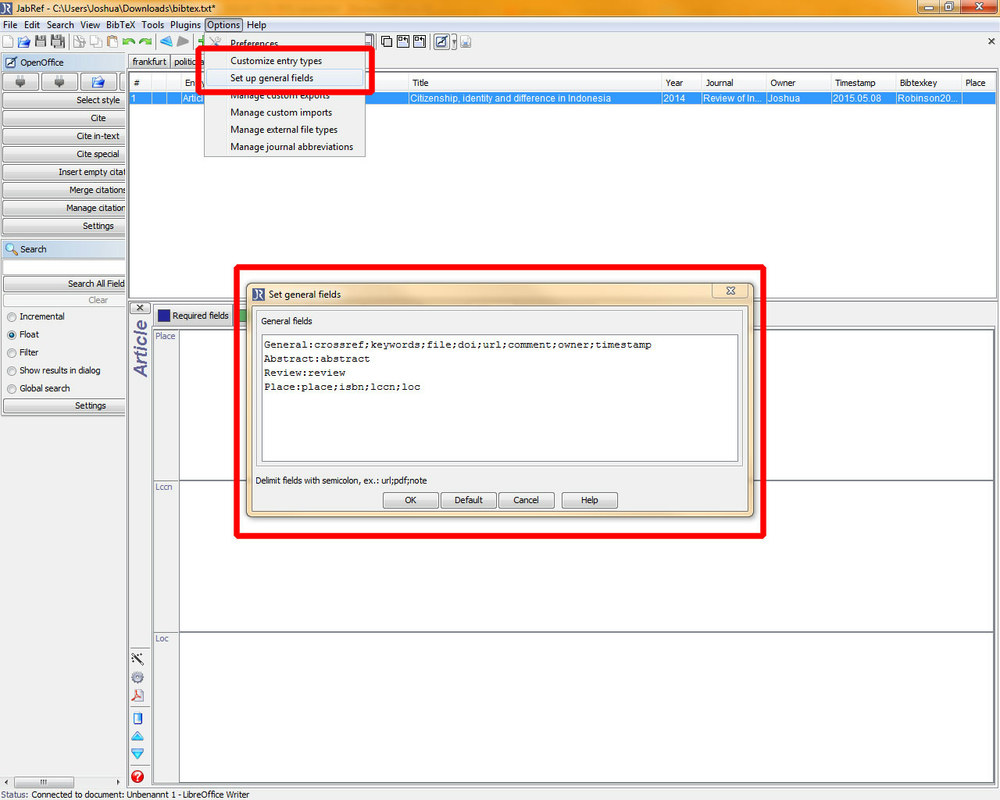
Wie man im Screenshot sehen kann, habe ich vier zusätzliche Felder eingefügt: "place", „isbn", „lccn", „loc". Im Hintergrund kann man den Inhalt des gerade geöffneten Reiters „Place" sehen, „isbn" erscheint aber nicht als Eingabeoption, weil ich noch nicht OK gedrückt habe. Ab jetzt können die selbst hinzugefügten Felder genau wie die standartmäßig gegebenen benutzt werden. Das sieht zum Beispiel so aus:
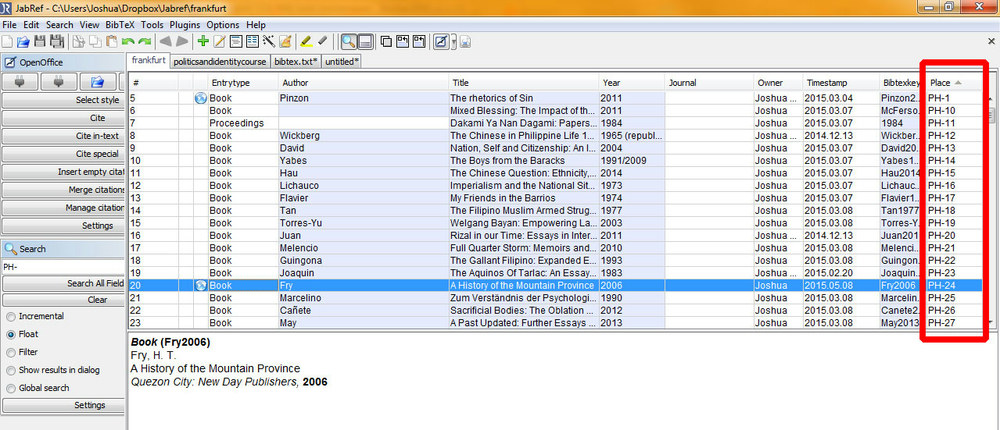
Formate
JabRef speichert seine Daten im BibTeX-Format (Wikipedia-Eintrag hier), das kann man zum Beispiel sehen, wenn man den Reiter „BibTeX Source" in der Eingabemaske sieht. Hier werden die Informationen zu einem einzelnen Eintrag gezeigt. Alle BibTeX Einträge gesammelt kann man sehen, indem man einfach die Datenbank-Datei in einem Text-Editor (Zum Beispiel der Windows Editor, Word, Open Office, usw.) öffnet. Für Bernhard Dahms José Rizal: Der Nationalheld der Filipinos sieht das zum Beispiel so aus.
\@BOOK{Dahm1989,
title = {José Rizal: Der Nationalheld der Filipinos},
publisher = {Göttingen: Muster-Schmidt Verlag},
year = {1989},
author = {Bernhard Dahm},
series = {Persönlichkeit und Geschichte, Bd. 134},
keywords = {Rizal
José Rizal y Mercado
Philippinen
Spanische Kolonialzeit
Kolonialismus
},
timestamp = {2013.07.07}
}
@BOOK bedeutet, dass es sich um ein Buch (und z.B. nicht einen Artikel) handelt. Als nächstes folgen der BibTeX-Schlüssel und dann die einzelnen Merkmale des Buches innerhalb von geschwungenen Klammern. Das Buch wurde also 1989 veröffentlicht - year = {1989} - und am siebten Juli 2013 eingegeben - timestamp = {2013.07.07}.
JabRef unterstützt für Importe und Exporte auch andere Formate, zum Beispiel MODS (hier der Wikipedia-Eintrag) und RIS.
Wichtig sind diese Formate vor allem weil sie die wichtigste Möglichkeit zum Austausch von Informationen zwischen verschiedenen Programmen mit bibliographischen Informationen bieten. Konkret bedeutet das, dass viele Seiten die Möglichkeit geben, dass man bibliographische Informationen in einem dieser Formate exportiert. Im Kleinen haben zum Beispiel die Publikationsunterseiten dieser Seite Exportfunktionen für die genannten drei Formate. Im Großen bietet z.B. Google Books dieselben Exportfunktionen.
Zusätzlich gibt es auf einigen Seiten gesamte bibliographische Datenbanken in diesen Formaten zu downloaden, z.B. eine Datenbank mit bibliographischen Informationen zu tausenden linguistischen Werken bei Glottolog. Auch gibt es mittlerweile Tools, die Datenbanken anzapfen, z.B. bibliographische Informationen automatisch mithilfe der ISBN eines Buches extrahieren, sie umwandeln und als BibTeX ausgeben, zum Beispiel hier2.
Hat man nun also eine dieser Datenquellen benutzt und die entsprechenden bibliographischen Informationen in einem maschinenlesbaren Format heruntergeladen, muss man sie nur noch per Drag-and-Drop in ein JabRef-Fenster ziehen. Hier werden sie nun importiert und man hat ohne irgendetwas abzutippen die gewünschten Informationen im Programm.
Workaround über die Cloud und Refmaster
Zum Schluss noch etwas zur geräteübergreifenden Benutzung. JabRef hat im Gegensatz zu z.B. Zotero nicht von Haus aus eine Funktion zur geräteunabhängigen Nutzung. Das lässt sich aber mithilfe von selbstständigen Cloud-Programmen wie Dropbox oder Spideroak oder einem FTP-Speicher umgehen.
Dadurch das JabRef nur ein einfaches Textdokument zum Speichern der Datenbank benutzt, kann die Datei in den synchronisierten Ordner gelegt werden und ist ab da auf allen synchronisierten Geräten verfügbar. Hier kann sie dann mit JabRef geöffnet werden.
Für mobile Geräte muss man auf Alternativen ausweichen, z.B. Refmaster für Android. Refmaster funktioniert effektiv wie JabRef angepasst auf den kleineren Bildschirm eines Smartphones und mit wesentlich weniger Funktionen, reicht aber, um unterwegs schnell bibliographische Angaben nachzuschlagen, vor allem wenn man sich an den Namen des Autors erinnert.
Anmerkungen
Citavi wird nicht beachtet, weil die kostenlose Lizenz solange zur Verfügung steht, wie man an der Universität beschäftigt/eingeschrieben ist. Danach ist mindestens die eingewöhnte Arbeitsumgebung weg, im Schlimmstfall die Datenbank - oder man zahlt für etwas, das man genauso gut kostenlos bekommen kann.
Die verlinkte Seite benutzt die leider unvollständige Amazon API. Um ein einigermaßen umfassendes und korrektes Programm auf diese Art zu bauen, müsste man mehrere Quellen miteinander vergleichen, dies wird aber von den Firmen hinter den Datenbanken, also Amazon, Google etc. effektiv nicht gestattet.