Today I gave a presentation at the weekly colloquium of the Institute of Southeast Asian Studies on the creation and use of (electronical) bibliographical databases. The first part of the presentation was a general introduction to the topic. I discussed why it might actually make sense to create and use bibliographical databases and presented how to enter entries into these using either Zotero or JabRef. I then proceeded by discussing the different standards for saving bibliographical data and the use of the respective export functions. My slides can be found here, and interested readers - who are also able to read German - might want to read this topical blog article I wrote quite a while ago.
Building on the given information I proposed a new tool, which I have been working on since the Christmas vacation, for use at the institute. In this post I will first outline my motivations for creating and spreading it and its functions to then note down a bit of the discussion.
Motivation
During one class at the Institute students were told, I am paraphrasing, that at Cornell there is much money and few students, and, in contrast, that all Frankfurt had were "the masses". My natural reaction was thinking: "But the masses hold the power". Just that, commonly, they are too badly organized and not cooperating enough to use it. While this is a very general idea on the role of "the masses" in politics and society, it can be applied to inter-university comparisons just as well. If there were a way to organize a large part of the student body and make them cooperate more effectively, we could get much more done.
Unrelated, I created a tool to monitor my reading behavior and keep track of notable quotations over the Christmas vacations. Once I had implemented these basic functions, I quite quickly came back to thinking about how to better facilitate intellectual exchange at the institute.
The reading tool seemed to be well-suited for this purpose, if the right functions were added. Why? Southeast Asian Studies as a science, and all the more as a course at university, is very focused on work on texts. Generally, research findings - either found from work on texts or from direct field work at the country - needs to be situated in the larger picture, which is formed by monographies, articles and so on. Even with topics intensive on field work, lecturers might start reading students" papers "from behind", say, checking the bibliography"s length before anything else. Thus our reading can be said to be the foundation, or at least the lowest common denominator, of and in our studies of Southeast Asia.
On a more practical level: given what texts someone reads, others might be able to recognize interests and knowledge in a person. If there was a system to let the others know about one"s reading, this would surely enable people with shared interests or research topics to find each other more easily. Bringing them together and having them know about the shared interest would then most likely also lead to better cooperation (e.g. one telling the other about good topical sources, which the other person has yet to read).
Given these considerations it was pretty easy to figure out the necessary adjustments to the tool to make it potentially usable on at least an Institute-wide level.
The "Books" Tool
In this subsection I present a small description of the tool. A longer one can be found on my documentation page for it.
The Books tool was primarily written to monitor one"s own reading behavior in terms of pages of a book read a day, note down notable quotations and write reviews. For this, it reads bibliographical databases exported into the MODS specification of XML and displays bibliographical data from these.
After deciding to add functions for collaborative use to the Books tool, the tool now reads all uploaded bibliographies, of all users, to create one large database. This database can then be used by all users - and exported for use in their preferred software (be it JabRef, Zotero, Citavi, Endnote, or whatever). Thus no potential user is forced to give up on their usual routine, while collaboration and collective, aggregate input helps all users.
A second notable function is the "ranking" function. Using this, users can find other users - ranked by how many texts they added to their account on a given topic (say, which have been tagged as being topical). Next to the ranked users those keywords will be shown, which most strongly correlate in the users reading with the one entered as a search term. For example, searching for the "Philippines", the tool will show that most texts on the Philippines I read also dealt with labor migration and gender. This tool is aimed at pushing better communication and further collaboration outside of the context of the Books tool.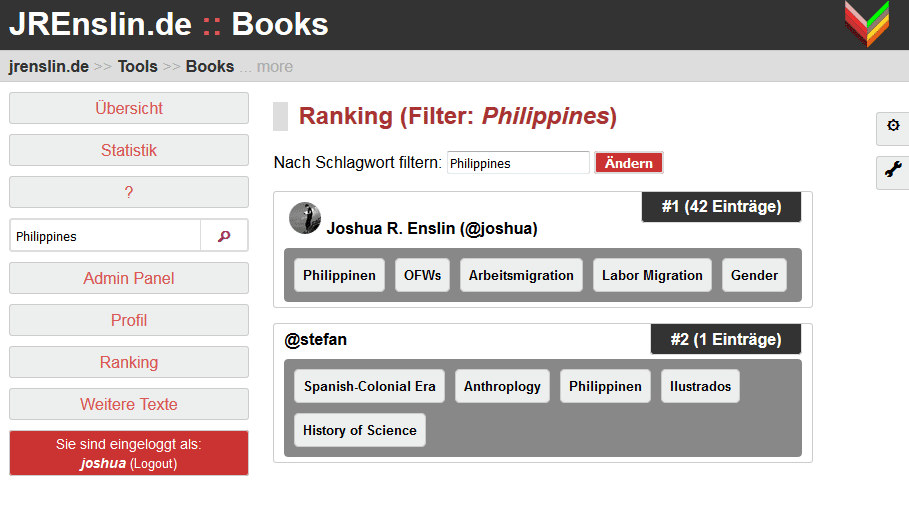
I will keep it at this very brief and selective description, further information can be found at the previously linked documentation page. Also, readers might just want to check out the tool themselves (accounts can be requested at the bottom - they will need to give me a good reason formulated in more than 50 characters to have it enabled though). It can be found here.
Today's Discussion
In this subsection I note down a summary of the questions and answers of the discussion on the Books tool. The reception was generally positive, and I was rather happy with how the presentation went. Read more below.
Can the tool be shared with users who do not know German?
Yes. Currently, the tool is available in three languages: English, German, and Indonesian. This can be further extended by downloading the dictionary file and adding the translations in XML.
Can PDF files be uploaded or how can actual texts be shared? What about copyright?
PDF files cannot be uploaded, exactly because of copyright concerns. User uploads are restricted to XML files. Users can nevertheless just contact each other after having found out that someone else has read a book. Contact information can be provided on a user"s profile page. Also, I am thinking about adding the possibility for users to enter information on whether they have access to a text, e.g. by owning it, or not.
What happens if the student who does it graduates?
There are full export functions for user data and bibliographical data, both personal as well as aggregate. The source code of the tool is available upon request (I am just not yet putting it out as open source because I am still slightly anxious about the login script). Thus migrating it to a different server without losing any data is very easy and possible at any time, also while I am still at the Institute.
The tool cannot be found using Google. Is that on purpose?
The technical structure of the tool makes indexing by Google very hard. Theoretically, almost all data is public, but a variable needs to be added to the URL to get to the public version. Private is the default.
How can pages created using the tool be shared with others?
Through a link to the page. Quite simply, add &peek=xyz where xyz is your username to the URL.
What if someone adds wrong keywords?
Since the aggregate data of all the different users is used, this possibility is quite irrelevant. If the majority enters accurate information, a single "mis-tagger" will not matter much.
What are the advantages of Zotero and JabRef and the Books tool over simply using Worldcat?
They simply serve different purposes. Zotero or JabRef are much more open and you are free to enter your own data which may be more accurate, comprehensive etc. than that of the librarians (and apprentices) adding data to Worldcat. Similarly, you cannot enter reading information to Worldcat. On the other hand, you also cannot use Zotero or JabRef to find a book in all the different libraries entering their data into Worldcat.
(The order of the questions is not accurate. I unfortunately noted down the questions too late and had already forgotten the precise order. I also took the liberty to add some additional information in the answer section.)